La Place des Développeurs FUSION-C Compression / Decompression RLE

La Compression RLEWB (Run Lenght Encoding)
En français dans le texte, on parle de "Concaténation de points". Ce système de compression est particulièrement adapté à la compression d'images, mais peut aussi être efficace pour d'autres données, à partir du moment où de nombreux éléments consécutifs redondant sont présent. La compression RLE est une compression sans aucune perte de données.
De plus la compression RLE est facile à comprendre et à mettre en œuvre. La compression ou la décompression RLE ne nécessite pas particulièrement de puissance de calcul. Elle est tout à fait adaptée à un usage sur les ordinateurs 8bits comme le MSX.
Il existe plusieurs variantes d'encodage, ici nous allons utiliser une variante que l'on va nommer RLEWB ; WB pour Wonder Boy, car cette compression est issue du jeu Wonder Boy Pour Sega Master System.
Comment ça marche ?
Prenant pour exemple un bloc de données comme celui-ci:

Ici nous avons une série de 42 Octets.
Certains octets contigus sont identiques voyons cela ...

Pour chacune des séries d'octets identique on va encoder de la manière suivante :
[Code de contrôle] [Nombre de répétitions] [valeur à répéter]
Le code de contrôle que nous utilisons arbitrairement est 0x80
On constate que les 5 premiers octets du bloc de données se répètent, on a 5 fois la valeur 0xE0, nous allons donc l'encoder et obtenir la séquence suivante :
0x80 0x05 0xE0
Que veut dire cette séquence lors de la décompression des données ? Si on trouve le code 0x80, alors on répète 5 fois la valeur 0xE0.
A la suite de cette première séquence on a une valeur isolée : 0x23. Le principe de la compression RLE se base sur les données continues et identique, donc cet octet ne sera pas encodé, et viendra à la suite tel quel, nous avons donc maintenant la séquence :
0x80 0x05 0xE0 0x23
Notons tout de suite que nous gérons des suites de données identique allant de 2 à 254 répétitions.
En continuant notre inspection du bloc de données, nous rencontrons une nouvelle série de données identique, 8 fois la valeur 0xE1, on encode la séquence comme précédemment, à la suite de notre séquence de données compressées :
0x80 0x05 0xE0 0x23 0x80 0x08 0xE1
La prochaine donnée nous pose problème : 0x80. En effet cette donnée, est aussi notre code de contrôle. Pour que la fonction de décompression puisse faire la différence entre 0x80 en tant que donnée, et le 0x80 en tant que code de contrôle, nous allons l'encoder d'une façon spécifique : 0x80 0x00. Quand la fonction de décompression rencontrera la séquence 0x80 0x00, cela veut dire que la donnée à écrire est 0x80 (Une donnée).
0x80 0x05 0xE0 0x23 0x80 0x08 0xE1 0x80 0x00
On continue notre encodage avec des données isolées, qui intègrent tel quels notre bloc compressé :
0x80 0x05 0xE0 0x23 0x80 0x08 0xE1 0x80 0x00 0x97 0xA1
Puis à nouveau une valeur 0x80 à intégrée, et des données isolées :
0x80 0x05 0xE0 0x23 0x80 0x08 0xE1 0x80 0x00 0x97 0xA1 0x80 0x00 0xAA 0xFA
Continuons... au final la séquence complète sera :
0x80 0x05 0xE0 0x23 0x80 0x08 0xE1 0x80 0x00 0x97 0xA1 0x80 0x00 0xAA
0xFA 0x80 0x04 0x82 0x71 0x80 0x02 0x09 0x78 0x80 0x04 0x91 0x80 0x0A
0x01
Nous obtenons une séquence compressée de 29 octets. Comparé aux 42 octets de départ, cela fait un gain de 13 octets, soit une compression d'environ 30 %.
Bien entendu, le gain n'est pas identique pour tous les types de fichier, et même pour certains fichiers, le résultat compressé peut s'avérer plus volumineux que l'original.
Un dernier point sur la compression.
Pour terminer notre séquence compressée nous avons choisi d'ajouter à la fin de la séquence le code : Ox80 0xFF qui indique la fin du fichier. Grâce à ce code de fin, il n'est pas nécessaire de connaitre la taille du bloc de données compressée. La décompression des données se terminera dès que la séquence 0x80 0xFF sera trouvée par la routine de décompression.
Le bloc de données compressée final sera donc :
0x80 0x05 0xE0 0x23 0x80 0x08 0xE1 0x80 0x00 0x97 0xA1 0x80 0x00 0xAA 0xFA 0x80 0x04 0x82 0x71 0x80 0x02 0x09 0x78 0x80 0x04 0x91 0x80 0x0A 0x01 0x80 0xFF
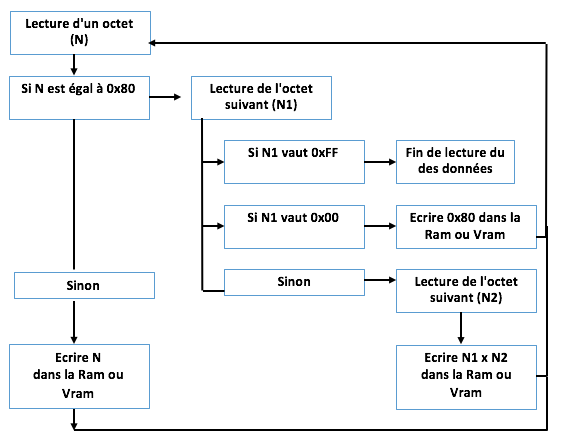
La fonction de décompression RLE-WB de FUSION-C est réalisée en assembleur, elle est très rapide. Il existe une fonction spécifique pour décompresser directement dans la VRAM, et une pour décompresser dans la RAM.
La fonction de décompression fonctionne de manière inverse à la compression.
Utilisation du compresseur RLEWB
L'outil de compression s'utilise en ligne de commande, sur Windows / MacOs / Linux. Ouvrez le DOS / Shell et utilisez cette syntaxe :
rlewb <Input file> <Output file> <Start offset> <Export mode> [End Encoding]
- <Input file> : est le fichier que vous désirez compresser
- <Output file> : est le fichier généré par l'outil, le type de fichier dépend du mode utilisé
- <Start Offset> : Indique l'octet où commencer la compression dans le fichier source. Utile pour ne pas compresser l'entête d'un fichier par exemple.
- <Export mode> : peux prendre 3 valeurs. 1, 2, ou 3.
1 : Le fichier de destination sera un fichier texte contenant des données intégrables dans un code source en assembleur
2 : Le fichier de destination sera un fichier texte contenant des données intégrables dans un code source C
3 : Le fichier de destination sera un fichier binaire sans entête
- [End Encoding (Optionnel)] : Par défaut la compression commencera à "Start Offset" et se terminera à la fin du fichier source. Ce paramètre optionnel permet de déterminer le numéro de l'octet auquel la compression s'arrête. (Utile pour ne pas compresser tout un fichier)
Exemples
rlewb mona.sc5 mona.asm 7 1
Va compresser le fichier mona.sc5, et exporter les données compressée dans un fichier texte mona.asm. La compression va commencer à l'octet 8 pour passer les 7 octets de l'entête du fichier et se termina à la fin du fichier.
Le fichier de destination comprendra ce genre de données :

rlewb mona.sc5 mona.c 7 2
Va compresser le fichier mona.sc5, et exporter les données compressée dans un fichier texte mona.c La compression va commencer à l'octet 8 pour passer les 7 octets de l'entête du fichier et se termina à la fin du fichier.
Le fichier de destination comprendra ce genre de données :

rlewb image.sc8 image.rle 30727 3 43527
Va compresser le fichier "image.sc8", et exporter les données compressées dans un fichier binaire "image.rle". La compression va commencer à l'octet 30727 du fichier source et se terminer à l'octet 43527.
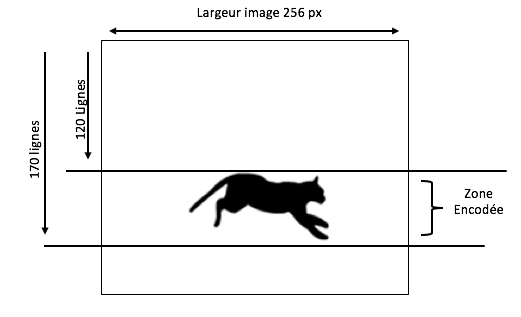
Pourquoi ces nombres ? Parce que l'on souhaite compresser qu'une zone de 50 lignes de pixels seulement, située entre les lignes 120 et 170.
Nous avons à faire avec un fichier .SC8, dont chaque octet après l'entête du fichier correspond à la couleur d'un pixel. Le nombre de pixels sur la largeur d'une image .SC8 est de 256 pixels.
(30727 - 7) / 256 = 120
(43527 - 7) / 256 = 170
[/size]
Utilisation des fonctions dédiées dans fusion-C

Package
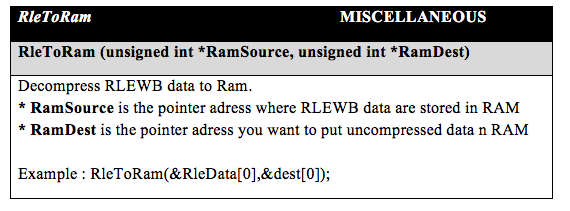
Dans le package se trouvent les fonctions RleToRam et RleToVram que vous pouvez intégrer dans vos programmes C.
Ces fonctions seront directement intégrées comme tel dans la prochaine mise à jour de Fusion-C
Le compresseur RLEWB
Code source en C, ainsi que les executables Windows64/MacOs/Linux
Package Fusion-C-RLEWB.zip
Edité par ericb59 Le 19/03/2019 à 05h45
En français dans le texte, on parle de "Concaténation de points". Ce système de compression est particulièrement adapté à la compression d'images, mais peut aussi être efficace pour d'autres données, à partir du moment où de nombreux éléments consécutifs redondant sont présent. La compression RLE est une compression sans aucune perte de données.
De plus la compression RLE est facile à comprendre et à mettre en œuvre. La compression ou la décompression RLE ne nécessite pas particulièrement de puissance de calcul. Elle est tout à fait adaptée à un usage sur les ordinateurs 8bits comme le MSX.
Il existe plusieurs variantes d'encodage, ici nous allons utiliser une variante que l'on va nommer RLEWB ; WB pour Wonder Boy, car cette compression est issue du jeu Wonder Boy Pour Sega Master System.
Comment ça marche ?
Prenant pour exemple un bloc de données comme celui-ci:
Ici nous avons une série de 42 Octets.
Certains octets contigus sont identiques voyons cela ...
Pour chacune des séries d'octets identique on va encoder de la manière suivante :
[Code de contrôle] [Nombre de répétitions] [valeur à répéter]
Le code de contrôle que nous utilisons arbitrairement est 0x80
On constate que les 5 premiers octets du bloc de données se répètent, on a 5 fois la valeur 0xE0, nous allons donc l'encoder et obtenir la séquence suivante :
0x80 0x05 0xE0
Que veut dire cette séquence lors de la décompression des données ? Si on trouve le code 0x80, alors on répète 5 fois la valeur 0xE0.
A la suite de cette première séquence on a une valeur isolée : 0x23. Le principe de la compression RLE se base sur les données continues et identique, donc cet octet ne sera pas encodé, et viendra à la suite tel quel, nous avons donc maintenant la séquence :
0x80 0x05 0xE0 0x23
Notons tout de suite que nous gérons des suites de données identique allant de 2 à 254 répétitions.
En continuant notre inspection du bloc de données, nous rencontrons une nouvelle série de données identique, 8 fois la valeur 0xE1, on encode la séquence comme précédemment, à la suite de notre séquence de données compressées :
0x80 0x05 0xE0 0x23 0x80 0x08 0xE1
La prochaine donnée nous pose problème : 0x80. En effet cette donnée, est aussi notre code de contrôle. Pour que la fonction de décompression puisse faire la différence entre 0x80 en tant que donnée, et le 0x80 en tant que code de contrôle, nous allons l'encoder d'une façon spécifique : 0x80 0x00. Quand la fonction de décompression rencontrera la séquence 0x80 0x00, cela veut dire que la donnée à écrire est 0x80 (Une donnée).
0x80 0x05 0xE0 0x23 0x80 0x08 0xE1 0x80 0x00
On continue notre encodage avec des données isolées, qui intègrent tel quels notre bloc compressé :
0x80 0x05 0xE0 0x23 0x80 0x08 0xE1 0x80 0x00 0x97 0xA1
Puis à nouveau une valeur 0x80 à intégrée, et des données isolées :
0x80 0x05 0xE0 0x23 0x80 0x08 0xE1 0x80 0x00 0x97 0xA1 0x80 0x00 0xAA 0xFA
Continuons... au final la séquence complète sera :
0x80 0x05 0xE0 0x23 0x80 0x08 0xE1 0x80 0x00 0x97 0xA1 0x80 0x00 0xAA
0xFA 0x80 0x04 0x82 0x71 0x80 0x02 0x09 0x78 0x80 0x04 0x91 0x80 0x0A
0x01
Nous obtenons une séquence compressée de 29 octets. Comparé aux 42 octets de départ, cela fait un gain de 13 octets, soit une compression d'environ 30 %.
Bien entendu, le gain n'est pas identique pour tous les types de fichier, et même pour certains fichiers, le résultat compressé peut s'avérer plus volumineux que l'original.
Un dernier point sur la compression.
Pour terminer notre séquence compressée nous avons choisi d'ajouter à la fin de la séquence le code : Ox80 0xFF qui indique la fin du fichier. Grâce à ce code de fin, il n'est pas nécessaire de connaitre la taille du bloc de données compressée. La décompression des données se terminera dès que la séquence 0x80 0xFF sera trouvée par la routine de décompression.
Le bloc de données compressée final sera donc :
0x80 0x05 0xE0 0x23 0x80 0x08 0xE1 0x80 0x00 0x97 0xA1 0x80 0x00 0xAA 0xFA 0x80 0x04 0x82 0x71 0x80 0x02 0x09 0x78 0x80 0x04 0x91 0x80 0x0A 0x01 0x80 0xFF
La fonction de décompression RLE-WB de FUSION-C est réalisée en assembleur, elle est très rapide. Il existe une fonction spécifique pour décompresser directement dans la VRAM, et une pour décompresser dans la RAM.
La fonction de décompression fonctionne de manière inverse à la compression.
Utilisation du compresseur RLEWB
L'outil de compression s'utilise en ligne de commande, sur Windows / MacOs / Linux. Ouvrez le DOS / Shell et utilisez cette syntaxe :
rlewb <Input file> <Output file> <Start offset> <Export mode> [End Encoding]
- <Input file> : est le fichier que vous désirez compresser
- <Output file> : est le fichier généré par l'outil, le type de fichier dépend du mode utilisé
- <Start Offset> : Indique l'octet où commencer la compression dans le fichier source. Utile pour ne pas compresser l'entête d'un fichier par exemple.
- <Export mode> : peux prendre 3 valeurs. 1, 2, ou 3.
1 : Le fichier de destination sera un fichier texte contenant des données intégrables dans un code source en assembleur
2 : Le fichier de destination sera un fichier texte contenant des données intégrables dans un code source C
3 : Le fichier de destination sera un fichier binaire sans entête
- [End Encoding (Optionnel)] : Par défaut la compression commencera à "Start Offset" et se terminera à la fin du fichier source. Ce paramètre optionnel permet de déterminer le numéro de l'octet auquel la compression s'arrête. (Utile pour ne pas compresser tout un fichier)
Exemples
rlewb mona.sc5 mona.asm 7 1
Va compresser le fichier mona.sc5, et exporter les données compressée dans un fichier texte mona.asm. La compression va commencer à l'octet 8 pour passer les 7 octets de l'entête du fichier et se termina à la fin du fichier.
Le fichier de destination comprendra ce genre de données :
rlewb mona.sc5 mona.c 7 2
Va compresser le fichier mona.sc5, et exporter les données compressée dans un fichier texte mona.c La compression va commencer à l'octet 8 pour passer les 7 octets de l'entête du fichier et se termina à la fin du fichier.
Le fichier de destination comprendra ce genre de données :
rlewb image.sc8 image.rle 30727 3 43527
Va compresser le fichier "image.sc8", et exporter les données compressées dans un fichier binaire "image.rle". La compression va commencer à l'octet 30727 du fichier source et se terminer à l'octet 43527.
Pourquoi ces nombres ? Parce que l'on souhaite compresser qu'une zone de 50 lignes de pixels seulement, située entre les lignes 120 et 170.
Nous avons à faire avec un fichier .SC8, dont chaque octet après l'entête du fichier correspond à la couleur d'un pixel. Le nombre de pixels sur la largeur d'une image .SC8 est de 256 pixels.
(30727 - 7) / 256 = 120
(43527 - 7) / 256 = 170
[/size]
Utilisation des fonctions dédiées dans fusion-C
Package
Dans le package se trouvent les fonctions RleToRam et RleToVram que vous pouvez intégrer dans vos programmes C.
Ces fonctions seront directement intégrées comme tel dans la prochaine mise à jour de Fusion-C
Le compresseur RLEWB
Code source en C, ainsi que les executables Windows64/MacOs/Linux
Package Fusion-C-RLEWB.zip
Edité par ericb59 Le 19/03/2019 à 05h45

@Sylvain, je ne pense pas que coder des suite de 255, 256 ou 257 octets identiques au lieu de 254 maximum, va vraiment changer quelque chose.
Par contre tu as raison pour une suite de 2 octets, on perd 1 octet dans la version compressée, il faudrait qu je traite les suites de 2 octets comme des éléments unique.
Une suite de 3 octets identiques ça ne change rien.
Par contre tu as raison pour une suite de 2 octets, on perd 1 octet dans la version compressée, il faudrait qu je traite les suites de 2 octets comme des éléments unique.
Une suite de 3 octets identiques ça ne change rien.
merci Éric ! 
peux-tu comparer la vitesse de décompression avec cette autre méthode ?
http://amigadev.elowar.com/read/ADCD_2.1/Devices_Manual_guide/node01C0.html
peux-tu comparer la vitesse de décompression avec cette autre méthode ?
http://amigadev.elowar.com/read/ADCD_2.1/Devices_Manual_guide/node01C0.html
DONALD TRUMP IS FAST APPROACHING
NEMESIS ! RETURN IMMEDIATELY !
Sector28_3 :
merci Éric !
peux-tu comparer la vitesse de décompression avec cette autre méthode ?
http://amigadev.elowar.com/read/ADCD_2.1/Devices_Manual_guide/node01C0.html
peux-tu comparer la vitesse de décompression avec cette autre méthode ?
http://amigadev.elowar.com/read/ADCD_2.1/Devices_Manual_guide/node01C0.html
Heuuu non... Car je ne comprend pas !

@Sector28_3 : d'accord j'ai compris, mais j'ai pas le temps de coder ca juste pour savoir "qui qu'à la plus grosse " 
Mais vas-y ... et tu nous dira ....
Mais vas-y ... et tu nous dira ....



Répondre
Vous n'êtes pas autorisé à écrire dans cette catégorie